Building Adaptive Ranking Systems for LLM-Scale Ad Models: A Practical Guide
Overview
Modern advertising platforms are increasingly turning to large language model (LLM)-scale recommendation systems to understand user intent and deliver personalized ads. However, deploying such massive models in real-time inference environments creates a fundamental tension: the need for high model complexity versus strict latency and cost constraints. This guide explores how to break this deadlock by adopting an adaptive ranking approach, inspired by Meta's recent innovations. You'll learn the three core innovations—inference-efficient scaling, model/hardware co-design, and reimagined serving infrastructure—that allow serving trillion-parameter models at sub-second latency. By the end, you'll have a blueprint for bending the inference scaling curve in your own recommendation systems.

Prerequisites
Before diving into adaptive ranking, ensure you have a solid understanding of:
- Recommendation systems fundamentals (candidate generation, ranking, blending).
- Large language models (transformer architectures, attention mechanisms, scaling properties).
- Inference optimization techniques (quantization, pruning, distillation, batching).
- Hardware architectures (GPUs, TPUs, memory bandwidth, interconnects).
- Latency and cost trade-offs in online serving systems.
Familiarity with Meta's Ads system or similar large-scale platforms is helpful but not required.
Step-by-Step Instructions
Step 1: Understand the Inference Trilemma
The first step is recognizing the core challenge. The inference trilemma involves three competing goals:
- Model complexity: Larger, deeper models capture richer user behaviors but demand more computation and memory.
- Latency: Real-time ads must return predictions in sub-second windows (often <100 ms).
- Cost efficiency: Serving billions of requests daily requires minimizing hardware and energy costs.
Traditional systems use a one-size-fits-all model, leading to either underperformance (if too small) or unacceptable latency/cost (if too large). Adaptive ranking resolves this by dynamically matching model complexity to each request's context.
Step 2: Design a Request-Centric Architecture
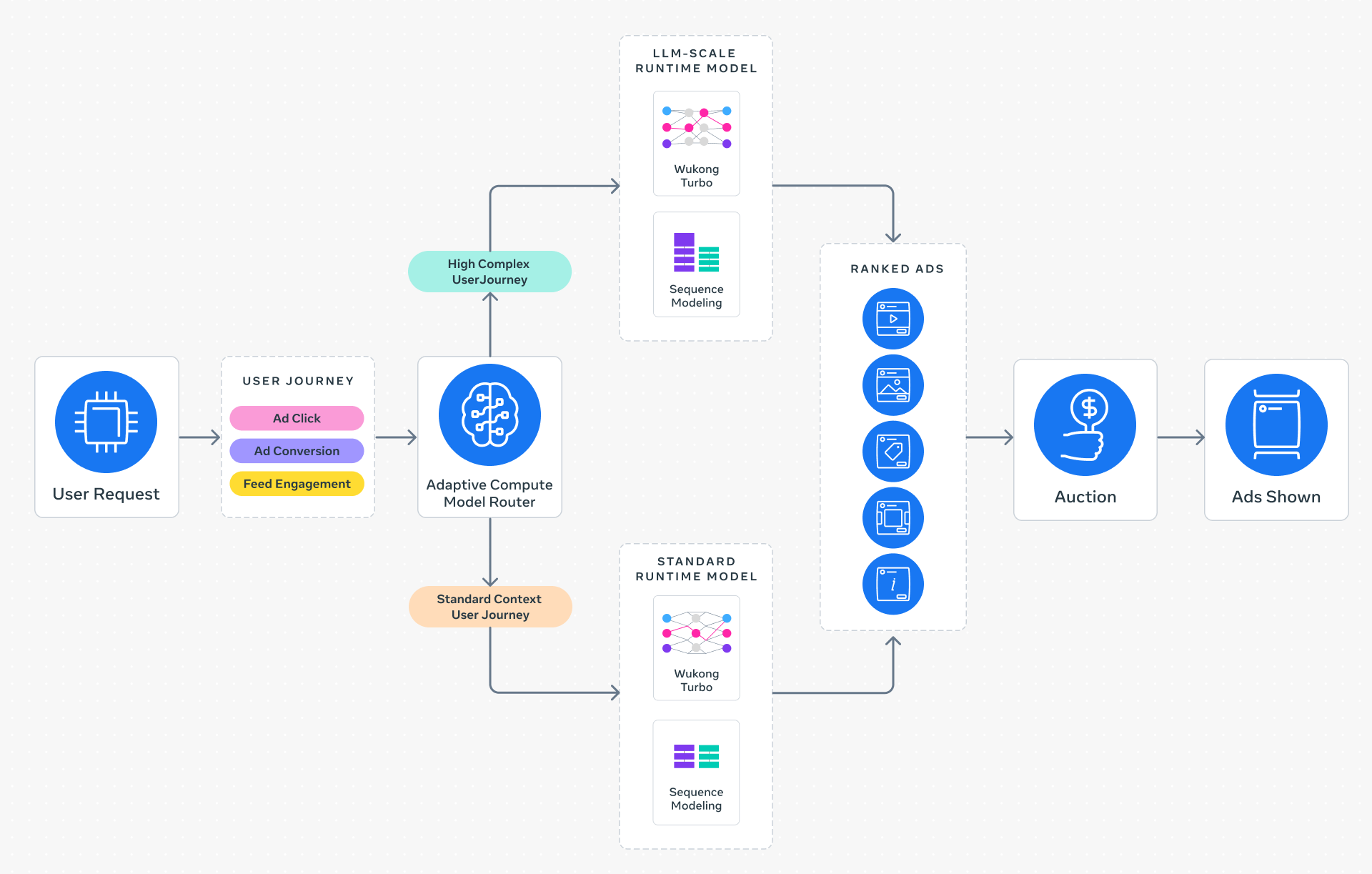
Replace the static model with a request-centric routing system. The key idea: for each incoming ad request, the system first determines the user's context (e.g., previous clicks, time of day, device type) and intent (e.g., browsing vs. ready to purchase). Based on this, it routes the request to a model instance of appropriate size and depth.
Implementation sketch:
1. Feature extractor produces a context vector.
2. A lightweight router model predicts the optimal model tier (e.g., small/medium/large).
3. The request is forwarded to the selected model for scoring.
4. The result is aggregated and returned within latency budget.
This architecture dramatically reduces average inference cost because most requests don't require the full LLM-scale model. Only the most complex or high-value requests use the largest network.
Step 3: Co-Design Model and Hardware
Efficiency gains from routing alone are insufficient for LLM-scale models. You must also align model design with hardware capabilities. This model/system co-design involves:
- Hardware-aware tensor shapes: Ensure matrix dimensions match GPU tile sizes to maximize tensor core utilization.
- Memory access patterns: Design attention heads to exploit high-bandwidth memory (HBM) and reduce off-chip transfers.
- Operator fusion: Combine multiple operations (e.g., linear + activation + dropout) into single kernel launches.
- Mixed precision: Use FP16/BF16 for forward pass while maintaining FP32 for critical accumulations.
Example: For an NVIDIA H100 GPU, a Transformer layer could be adjusted so that hidden dimension = 8192 (multiple of 256) and attention heads = 64 (multiple of 8), both aligning with tensor core processing units.
Step 4: Build Reimagined Serving Infrastructure
Supporting models with up to 1 trillion parameters demands a rethought serving stack. Key components:
- Model parallelism across cards: Shard the model across multiple GPUs using techniques like tensor parallelism (Megatron-LM) or pipeline parallelism. For ad serving, combined sharding with request routing ensures each model copy fits in aggregate memory.
- Intelligent batching: Group requests of similar model tiers together to maximize throughput while respecting latency SLOs.
- Caching: Cache intermediate layer outputs from frequent user profiles to avoid recomputation.
- Dynamic scaling: Use cluster autoscalers that spin up/down GPU instances based on traffic patterns (e.g., higher during evening peaks).
A practical serving setup might use Kubernetes with NVIDIA GPU operator, a custom inference server (e.g., Triton with modifications), and a routing layer (e.g., Envoy) that implements the request-classification logic.
Step 5: Measure ROI and Iterate
Deploying adaptive ranking is not a one-time event. Monitor these key metrics:
- Conversion rate and click-through rate (CTR) – the primary business KPIs.
- Average latency and p99 latency – ensure you stay under the sub-second threshold.
- Cost per inference – track GPU hours, memory utilization, and energy.
- System throughput – requests per second under load.
Regularly retrain the routing model to adapt to shifting user behavior. Meta reported a +3% improvement in conversions and +5% in CTR after launching adaptive ranking on Instagram in Q4 2025. Your mileage may vary; iterative tuning is essential.
Common Mistakes
Ignoring Latency Budgets During Model Design
Shoving a huge model into production without considering the end-to-end latency often leads to timeouts or degraded user experience. Always profile each routing path under full load.
Treating All Hardware as Equal
Deploying the same model configuration across heterogeneous hardware (e.g., A100s and H100s) wastes potential. Instead, tune the hardware-aware parameters for each cluster.
Overlooking Cold Start for New Users
Users with no history may be misclassified by the router. Provide a fallback tier (e.g., use a universal embedding lookup) to avoid routing errors.
Not Monitoring Router Accuracy
The routing model itself can drift. Periodically validate its predictions against actual performance of different model tiers to ensure high-quality selection.
Summary
Adaptive ranking replaces the one-size-fits-all inference approach with intelligent request routing, dynamically matching model complexity to user context. By implementing three key innovations—request-centric architecture, model/hardware co-design, and a reimagined serving infrastructure—you can serve LLM-scale recommendation models at sub-second latency while maintaining cost efficiency. Start by understanding the inference trilemma, then follow the steps to design, build, and iterate on your adaptive system. Avoid common pitfalls like ignoring latency budgets or hardware heterogeneity. The result: higher ad conversions, better user experiences, and sustainable scalability.