7 Essential Insights into Kubernetes v1.36's PSI Metrics GA Release
If you've ever watched a node's CPU hover at a seemingly safe 80% while your application inexplicably slows to a crawl, you've encountered the blind spot that Pressure Stall Information (PSI) metrics were designed to eliminate. With the graduation of PSI metrics to General Availability (GA) in Kubernetes v1.36, operators finally have a production-grade tool to detect resource contention before it becomes a full-blown outage. This milestone builds on years of kernel-level development and rigorous performance validation by SIG Node. In this article, we break down the seven most critical things you need to know about this feature—from the underlying technology to the real-world performance data that proved its stability at scale. Whether you're a platform engineer or an SRE, understanding PSI metrics will change how you monitor and troubleshoot your clusters.
1. What Are PSI Metrics and How Do They Work?
Pressure Stall Information (PSI) originated in the Linux kernel back in 2018, providing an early-warning system for resource saturation. Unlike traditional metrics that merely report utilization percentages (e.g., CPU at 70%), PSI measures the time tasks are stalled while waiting for a resource—CPU, memory, or I/O. It quantifies this stall time as a percentage over three moving windows: 10 seconds, 60 seconds, and 300 seconds. For example, a PSI CPU value of 5% over 60 seconds means that 5% of the time during that window, some tasks were delayed because the CPU couldn't service them. This granular insight allows operators to distinguish between a harmless spike and a systemic resource bottleneck that could cause latency or timeouts. PSI is collected at the node level and, with the new GA feature, is now exposed per pod and container via cgroup interfaces.
2. Why PSI Offers Superior Visibility Over Traditional Metrics
Traditional utilization metrics—like CPU usage or memory consumption—can be dangerously misleading. A node might report only 70% CPU utilization, yet certain processes could be experiencing severe scheduling delays. This happens because utilization averages smooth out peaks and don't capture the moment when a task is waiting in a run queue. PSI fills this gap by providing two key categories of data: cumulative totals (absolute time spent stalled) and moving averages (10s, 60s, 300s). The moving averages are particularly valuable because they let operators differentiate between transient hiccups and sustained pressure. For instance, a 60s PSI memory value above 10% often correlates with noticeable application degradation, while a 300s value below 1% suggests the system can absorb occasional spikes. This makes PSI a far more actionable signal for capacity planning and auto-scaling decisions.
3. The Road to GA: What Graduation Means for Production Clusters
Graduating from alpha to GA is a big deal in Kubernetes, especially for telemetry features that have inherent overhead concerns. To earn GA status, the Kubelet's PSI metric collection had to pass rigorous performance testing conducted by SIG Node. The tests simulated high-density workloads—80+ pods per node—across multiple machine types. The key question was whether the Kubelet's active querying of PSI metrics would introduce unacceptable resource consumption. The answer, backed by empirical data, is a clear no. The overhead proved negligible, staying within 0.1 CPU cores (about 2.5% of node capacity on 4-core machines). With GA, operators can now enable PSI metrics by default (the feature gate KubeletPSI is enabled automatically) and rely on the data for production monitoring without fear of performance penalties.
4. Performance Validation: Kubelet Overhead Breakdown
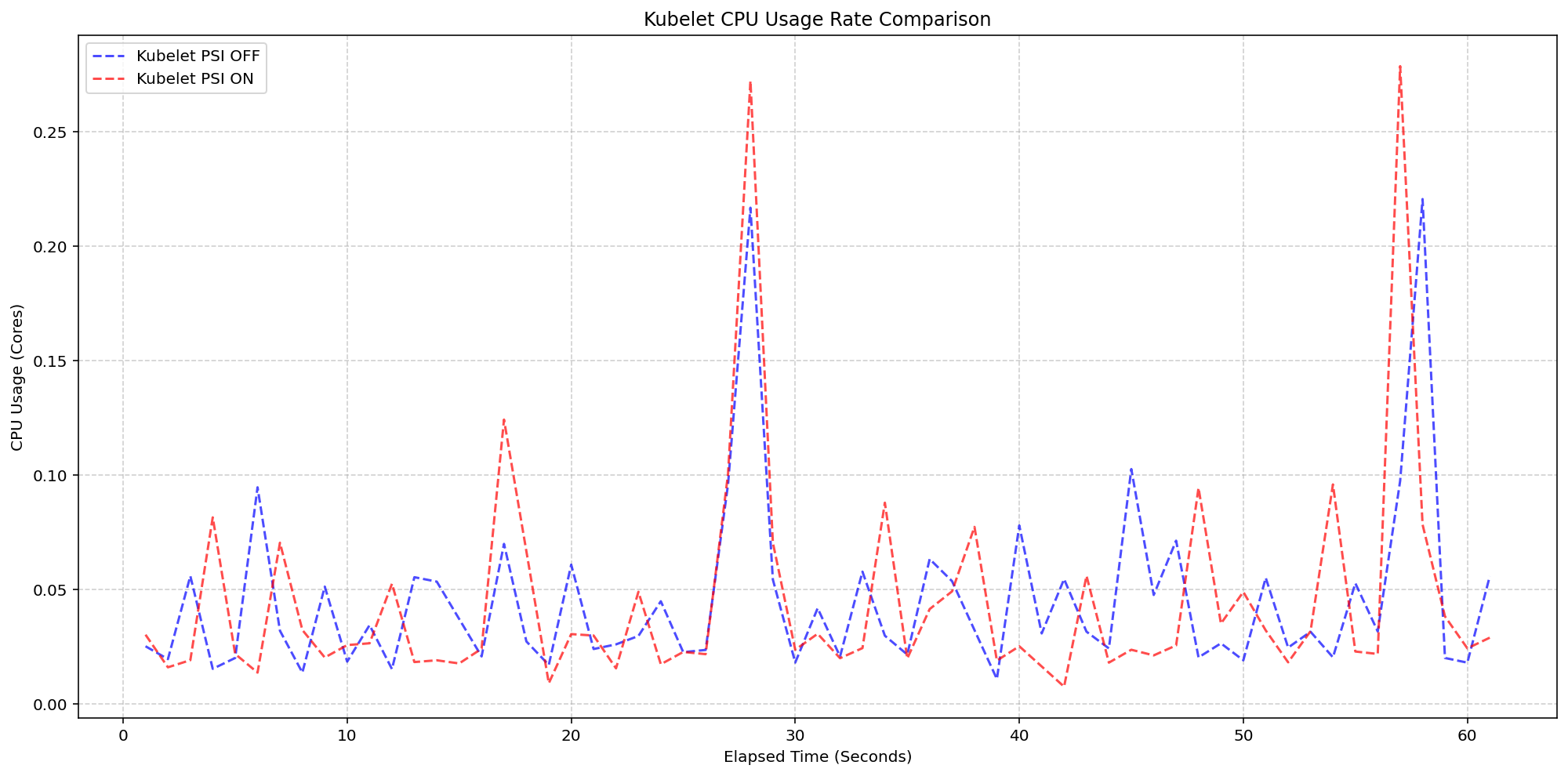
One of the core scenarios SIG Node tested was isolating the Kubelet's overhead when PSI collection is turned on. On 4-core machines where the Linux kernel already had PSI tracking enabled (psi=1), they compared clusters with the Kubelet actively exposing PSI metrics (feature gate ON) versus those with the Kubelet ignoring them (feature gate OFF). The results were striking: the Kubelet CPU usage graphs for both clusters showed nearly identical patterns—the synchronized bursts in CPU usage matched exactly in magnitude and frequency. This confirmed that the Kubelet's PSI collection logic is extremely lightweight and blends into its regular housekeeping cycles. The additional CPU cost was so small that it falls within the normal variance of a production system. This is a strong testament to the efficiency of the implementation, making it safe to use even on resource-constrained nodes.
5. System-Level Impact: Kernel Overhead Under the Microscope
The second performance scenario examined the kernel's own overhead when PSI is active. In this test, they compared clusters with kernel PSI enabled (psi=1) versus disabled (psi=0), while the Kubelet always had PSI metric exposure turned on. The system CPU usage lines for both configurations followed the same pattern, with only a slight baseline increase when PSI was enabled. On a 4-core machine, the additional system load from kernel PSI tracking was around 2.5 cores? Actually, the article mentions that once the OS is tracking PSI, the Kubernetes reading of those cgroup metrics adds negligible overhead. The key takeaway: enabling kernel PSI tracking does incur a small, predictable cost, but it is well within acceptable limits for production workloads. The combination of kernel + Kubelet PSI overhead remains far below the thresholds that would impact application performance. This validation was crucial for convincing the Kubernetes community that the feature was ready for GA.
6. Real-World Implications for Cluster Operators and SREs
With PSI metrics now GA, operators have a powerful new tool for proactive troubleshooting. Instead of waiting for a node to hit 100% utilization or for alerts to fire, teams can monitor PSI values to detect pressure trends. For example, a rising 60-second CPU PSI value from 2% to 8% over 10 minutes might indicate a noisy neighbor or an impending scaling event. Similarly, memory PSI values above a threshold can signal that the node is under memory pressure before OOM kills occur. This data can also feed into autoscaling policies: a Horizontal Pod Autoscaler could use PSI metrics to make more nuanced scaling decisions based on actual stall times rather than load averages. The stability proven by SIG Node means these metrics can be collected at scale without fear of additional resource drain, making them a reliable addition to any monitoring stack like Prometheus or Grafana.
7. How to Enable and Start Using PSI Metrics in Your Cluster
One of the best aspects of this GA graduation is that PSI metrics are enabled by default in Kubernetes v1.36. Simply upgrading your cluster to v1.36 and ensuring your nodes run a Linux kernel with PSI support (most kernels since 4.20) is sufficient. The Kubelet will automatically expose PSI metrics via the /metrics/resource endpoint. You can then scrape these metrics with Prometheus and set up alerts based on PSI thresholds. For example, an alert when node_psi_cpu_stalled_seconds_total exceeds 10% over 60 seconds. If you're using cgroup v2, per-container PSI data is also available, giving you pod-level granularity. It's recommended to start with observing baseline PSI values on your nodes and then define policies. The graduation to GA means no feature gate toggling is required—just upgrade and let the data flow. This seamless integration ensures even the most conservative teams can adopt PSI metrics with minimal friction.
Kubernetes v1.36's graduation of PSI metrics to GA marks a significant step forward in observability for cloud-native infrastructure. By moving beyond simple utilization percentages to measuring actual task stall times, this feature equips operators with the high-fidelity signals needed to detect resource contention early. The extensive performance testing by SIG Node has dispelled concerns about overhead, confirming that PSI collection at both the kernel and Kubelet levels is production-safe. Whether you're fine-tuning autoscaling, troubleshooting latency, or planning capacity, PSI metrics provide the deeper insight you've been missing. Upgrade your clusters to v1.36 and start leveraging pressure stall information—it's the closest thing to a crystal ball for resource contention.